献给会计的礼物(一)
灰熊研究院

人工智能给会计职业带来挑战,但同时人工智能也给会计职业带来更多机遇。挑战指的是人会被人工智能所替代;机遇指的是人可能利用人工智能把事情做得更快更好。对个人来说,人工智能究竟是挑战(工作岗位被机器人所替代),或者是机遇(也就是变成人工智能的设计者),取决于你是否能理解人工智能系统的运行机制和是否能掌握在会计业务中构建人工智能系统的技能。
那么怎样才能获得驾驭人工智能所需的技能呢?加拿大灰熊研究院将在未来几周分享厦门大学会计系陈亚盛教授设计的《人工智能会计三步学习法》来帮助每一位会计人员掌握使用人工智能的方法。一共分享三篇文章分别介绍这三步:第一步是了解人工智能的基本理论和运行机制;第二步是掌握一种人工智能(机器学习)的编程语言;第三步是亲手设计一个会计人工智能算法。
第一步:了解人工智能的基本理论和运行机制
人工智能是人创造的,能模仿人类进行思考,并有可能超越人类的计算机系统。按照学习方式进行分类,人工智能一般可以分为监督式学习、无监督式学习和强化学习三种学习方式。
(1)监督式学习
根据标准答案进行学习就是监督式学习。通过比较预测结果与标准答案之间的差异,不断调整算法模型的参数,使得计算机的预测结果逐渐逼近标准答案。监督式学习的常见算法包括K-近邻、支持向量机、人工神经网络、决策树、卷积神经网络和循环神经网络。
- K-近邻 (K-Nearest Neighbors, KNN)
K-近邻是一种分类算法,其原理类似于“近朱者赤,近墨者黑”,数据点之间的距离越近,相似度越高,越有可能归为同一类别。KNN方法的使用需要一些事先标记过类别的数据(训练数据),KNN根据各个不同方面的特征指标计算出每一个需要分类的数据记录(测试数据)与每一个标记过的数据记录之间的距离,找到与该测试数据距离最近的K个训练数据,并根据训练数据的类别和少数服从多数原则,确定测试数据的类别。例如,与测试数据距离最近的5个训练数据中有3个属于A类,1个属于B类和1个属于C类,那么该测试数据被归为A类。
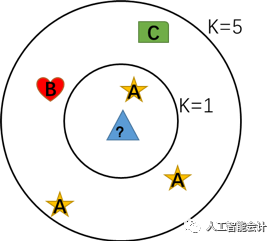
KNN在医疗辅助诊断上有广泛的应用,例如2013年Chen Hui-Ling等人在Expert Systems with Applications上发表的一篇文章中描述了KNN方法在帕金森综合症诊断中的应用。文章将已诊断病例作为训练数据,每个病例包含平均、最大、最小声音基频和音调噪声比等22个诊断特征以及最终确诊结果。当输入一个新病例时,机器将根据这22个诊断特征计算新病例与训练数据中所有病例的距离,选出与其距离最近的10个病例。若10个病例中患有帕金森综合症的个体占多数,则将该病例诊断为帕金森综合症;若10个案例中正常的个体占多数,则将该病例诊断为正常个案。除此之外,KNN还广泛运用在乳腺癌、肺结节等疾病的诊疗中。
- 支持向量机(Support Vector Machine, SVM)
支持向量机是一种适用于线性和非线性数据的分类算法,其目标在于找到将不同类别数据区分开来的分类标准。这个分类标准被称为超平面,组成超平面的训练数据被称为支持向量。SVM通过综合比较训练数据各个不同方面的特征指标找到n个能够将不同类别数据划分到不同区域的超平面,每个区域代表一种类别,使得不同类别数据之间的距离尽可能大,而相同类别数据之间的距离尽可能小。当输入新的测试数据时,只需要观察该数据所处的位置,就可以判断其类别。例如,综合分析三个维度的特征指标找到一个最优超平面把所有训练数据一分为二,超平面一侧的训练数据(绿色)都属于A类,而超平面另一侧的训练数据(橙色)都属于B类,根据测试数据所处位置就可以判断其类别,若处于超平面左侧则被判定为A类,若处于超平面右侧则被判定为B类。
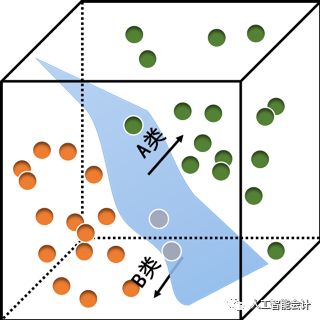
支持向量机的应用也很广泛,例如,根据中关村物联网产业联盟和国家物联网产业技术创新战略联盟共同举办的“2017年全球物联网大会”的报道,入围全球物联网创新成果的重庆广睿达科技有限公司正是运用SVM的原理实现大气污染物的快速溯源,将物联网、人工智能、大数据等技术与环保业务相互融合,通过污染物的各项检测指标,如一氧化碳浓度、扬尘、风向、气温等找到区分不同污染源的分类标准,也就是分类超平面,可以具体判断出哪些地方存在扬尘、废气排放等违法违规污染行为。
- 人工神经网络(Artificial Neural Network, ANN)
人工神经网络是运用得最广泛的监督式学习算法之一,既可以运用于分类问题,又可以运用于回归问题。ANN由输入层、隐藏层和输出层组成:输入层相当于自变量,输出层相当于因变量,而隐藏层则用于拟合输入与输出之间的关系。ANN把模型输出值与标准输出值之间的差值逐层反向传播到输出层,不断调整更新各层的连接参数,直到模型无限逼近标准输出值。
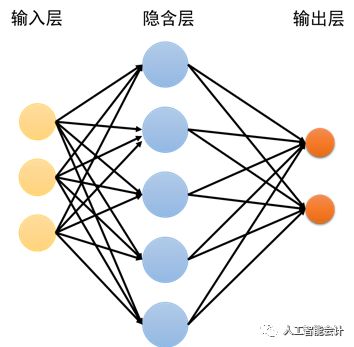
人工神经网络在智能选股方面有着不俗的表现,例如华泰金工林晓明团队在2017年11月公布的深度报告《人工智能系列之八:人工智能选股之全连接神经网络》中详细阐述了如何搭建一个具有2层隐藏层的人工神经网络进行智能选股:将成长因素、财务质量、杠杠、波动率、换手率、股价、投资者情绪等13大类的70个特征指标作为ANN的输入,尝试拟合各个特征指标与股票“涨跌平”情况之间复杂的非线性函数关系,从而完成股票在下一个自然月的涨跌预测,并根据预测输出的结果进行投资。在2011年1月31日至2017年的10月31日的测试期间,基于ANN预测模型的股票投资策略的年收益率在19.15%~25.36%之间,,在年化超额收益率、信息比率等指标上优于线性回归算法,投资表现优良。
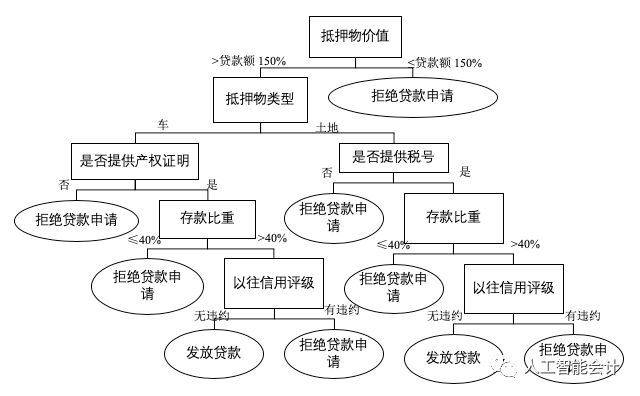
- 决策树(Decision Tree)
决策树由一个根节点、若干内部节点、叶节点和有向边组成:根节点和内部节点代表分类特征,叶节点代表分类类别,有向边则代表决策方向。决策树的关键在于特征指标的选择和排序,利用大量训练数据计算各特征指标的信息增益率、基尼系数等,找到分类能力最好的特征指标作为根节点,其他特征指标依次确认为各层级的内部节点。相比起其他算法,决策树能够还原决策的过程和步骤,简单直观,一目了然。
决策树算法凭借较强的解释能力,在决策判断领域广受欢迎。例如2012年Mandala等人在Procedia Economics & Finance发表的一篇文章描述了决策树算法帮助银行决定是否受理一项贷款申请的过程。文章以该银行已完成的贷款申请审批作为训练数据,通过计算信息增益率最终将“抵押物价值”确定为根节点(最重要的分类特征),将“抵押物类型”、“是否提供产权证明”、“是否提供税号”、“存款比重”和“以往信用评级”确定为内部节点,“拒绝贷款申请”和“发放贷款”则作为两个叶节点。银行工作人员只需要输入贷款申请信息,计算机就可以根据构建完成的决策树一步步完成贷款申请审批程序,提供是否发放贷款的决策建议,并向银行工作人员展示决策的全过程,比如说一个申请者存款比重超过40%且无违约记录,但抵押物价值只相当于贷款额的90%,计算机将基于抵押物价值没有超过贷款额的150%这一最重要的特征指标直接拒绝该项贷款申请。
- 卷积神经网络(Convolutional Neural Network, CNN)
卷积神经网络属于深度学习算法,其原理与ANN类似,特点体现在卷积层和池化层:卷积层相当于特征提取器,逐一提取原始数据中每一个小区域的特征;池化层则相当于特征压缩器,只保留最重要的信息。例如,用CNN识别图片中的狗,原始输入就是这幅图片,卷积操作将该图片划分成眼睛、耳朵以及尾巴等若干小区域,并进行特征提取,池化操作则保留各个区域最重要的特征,最后根据所有提取出来的特征综合判断图片中的动物是否为狗。卷积池化操作赋予了CNN强大的特征提取能力,使其拥有优于ANN的预测性能。
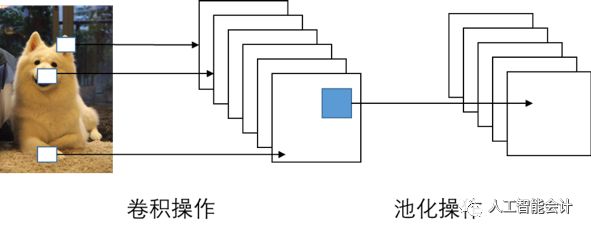
卷积神经网络的出现极大提高了计算机图像识别的能力,例如苹果公司在2017年九月发布的Iphone系列正是运用CNN的原理实现了用户脸部识别和解锁功能。在注册阶段,用户需拍摄2~3张图片作为标准人像,而在测试解锁阶段,则需连续多次输入新的3D人像,CNN通过多个卷积层和池化层不断提取输入人像的特征,例如眉毛、嘴巴、脸型、表情的特征等,并根据提取出来的特征计算输入人像与注册阶段拍摄的标准人像的距离,确定一个阈值,低于该阈值,则认为新输入与标准人像为同一人,可以解锁;高于该阈值,则认为新输入与标准人像不是同一人,解锁失败。随着用户使用次数的增加,内置的CNN会不断调整优化网络参数,预测准确率越来越高,即使化了妆、换了发型和做鬼脸依然可以识别出用户的脸部特征,顺利完成解锁。
- 循环神经网络(Recurrent Neural Network, RNN)
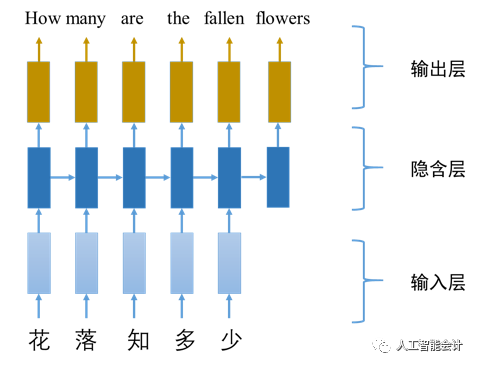
循环神经网络同属深度学习算法,其特点是将时间顺序考虑进来。如同我们在进行自然语言理解时不能单凭一个词或一句话就断章取义,需要结合上下文语境才能准确理解一样,RNN根据类似的原理将当前时刻的输入值、以前时刻的输入值以及输出值结合起来,共同决定当前时刻的输出值。例如,将孟浩然《春晓》中的一句古诗“花落知多少”翻译成英文时,由于中文表达中存在较多的倒序,逐字翻译法会导致译文十分生硬,甚至词不达意,RNN则在隐含层将前一时刻的输入和当前输入结合起来,比如说在翻译“落”的时候,计算机会把“花”同时考虑进来,将“花落”理解成“落下来的花朵”,进而将整句话翻译成“Howmany are the fallen flowers”。
循环神经网络特别适用于时间序列数据的分类与回归问题,例如百度外卖风控中心将RNN应用于商户和用户健康度的检测。百度外卖风控技术负责人王永会在2017年公开演讲中介绍,百度外卖通过输入商户类型、商户补贴、商户地址、拉新属性等商户属性、IP特征、定位地址、客单价、用户地址等订单特征以及物流轨迹等物流特征来识别作弊骗取平台补贴的商户和客户,并根据预测的作弊程度进行各种处罚,例如限制商户拉新、拉黑商户等。由于每位商户和用户的数据都是按天采集的,且作弊行为不仅与当天各项特征指标相关,与以往的行为轨迹也是息息相关,作弊行为的识别需要联系前后信息,所以RNN在健康度检测中具有较为理想的准确度,在实际应用中展现了良好的效果。
(2)无监督式学习
无监督式学习没有任何的标准答案可以学习,只能通过观察来发现数据内在的规律和结构,将具有类似特征的数据点归结在一起,使得同一类别的数据之间距离最小,而不同类别的数据之间距离最大。常见的无监督式学习算法包括K-均值。
- K-均值(K-means)
K-均值(K-means)是一种常见的聚类算法,其原理体现在“物以类聚”,根据特征指标把所有训练数据聚为K类,同一类的数据具有类似特征。例如,根据利润贡献和维护成本两个特征指标将某公司所有客户聚为4类,每类客户都具有类似的特点:红色区域的属于利润贡献大,维护成本低的明星客户,应该重点维持;黑色区域的属于利润贡献小,维护成本高的瘦狗客户,应尽早结束合作关系;蓝色区域的属于利润贡献大,维护成本也高的稳定型大客户,应适当控制维护成本;绿色区域的属于利润贡献和维护成本均低的稳定型小客户,无需过多关注。K-means既可以用于发现数据的分布结构,有助于使用者有针对性地分析具有类似特征的数据群体,也可以作为监督式学习的前驱过程,根据聚类结果对特征指标进行压缩,减少过多相似特征指标进入模型,提高运算速度和分类效果。
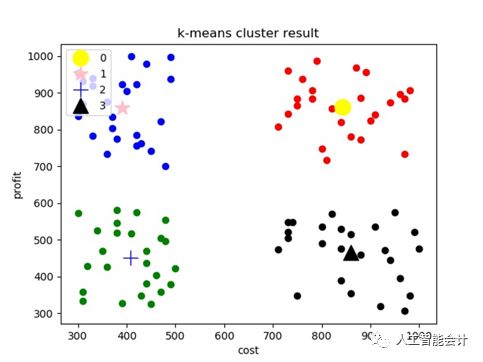
K-均值广泛运用在缺乏足够数据标签的模式发掘和识别问题中,例如全球领先的人工智能公司DataVisor就是利用包括K-means在内的无监督学习为企业提供反欺诈、反洗钱等金融犯罪检测服务。中国区总经理兼技术总监吴中在2017年向媒体解读了DataVisor在金融欺诈方面的关键技术:根据账户昵称、收入范围、年龄、性别等档案信息,业务操作类型、业务操作时间、支付金额、支付方式等行为信息,设备类型、设备版本、浏览器、IP地址等数字指纹信息以及不同账户之间的交互关系等数万个适用的特征指标,发现可疑账户在某些特征维度具有高度相似或存在隐藏关联的地方,这些账户将自动聚在一起;而其他正常账户由于具有不同的特点,仍然处于分散状态,通过不同的聚集状态就可以准确找出存在金融犯罪的欺诈账户。由于欺诈攻击的方式层出无穷、变化多端,监督式学习很难及时识别和更新所有欺诈模式,而无监督学习则可以通过分析特征指标的距离和连接自动发现新型的金融犯罪方式,提高对欺诈账户的动态应对能力。
(3)强化学习(Reinforcement Learning, RL)
强化学习是人工智能的一个重要分支,其原理体现在“摸着石头过河”。计算机从“零”开始逐步摸索解决问题的方案,如果执行的动作有利于最终目标的实现,则可以获得正面奖励,否则反之。计算机(Agent)每一步动作(Action)都会从系统环境(Environment)获得相应的奖励(Reward),根据该奖励调整下一步动作和行为策略,最终找到使得奖励最大化的决策路径。随着探索过程的深入,计算机有可能寻找到超越人类现有决策的方法。

策略型游戏中不乏强化学习的身影,例如2017年谷歌DeepMind团队在Nature发表的文章中详细介绍了强化学习在围棋领域的应用。在没有任何训练数据和人类经验的情况下,AlphaGo Zero从随机下子的瞎玩状态开始,每完成一局围棋游戏都会反思每一步落子对最终结果的影响,并据此计算每一步落子的奖励函数,落子越有利于取得最终胜利,获得的奖励越高。计算机根据奖励函数不断调整自己的落子策略,通过自我对弈逐渐学习和掌握围棋的规则和取胜的技巧,经过3天完全的自学训练,便以100:0的战绩击败了AlphaGo Lee和AlphoGo Master。
监督式学习、无监督式学习和强化学习各具特点,监督式学习适用于已知标准的分类问题和回归预测问题,无监督式学习适用于未知标准的归纳总结问题,而强化学习则适用于最优行动策略的探索问题。我们可以在理解各个机器学习算法原理和典型应用例子的基础上,掌握一种机器学习的编程语言,并尝试运用机器学习解决会计领域的问题。(未完待续。下一篇介绍“三步学习法”的第二步:掌握一种机器学习的编程语言,例如Python)